Sieve: A Middleware Approach to Scalable Access Control for Database Management Systems
The middleware implementation of Sieve (with connectors for both MySQL and PostgreSQL) and datasets are available at Github. You can also watch the 10 minute virtual presentation of Sieve from VLDB 2020 below. The full paper is available here.
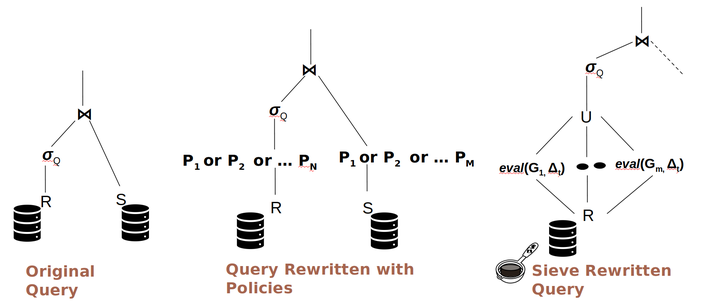
Sieve is a middleware system for efficient query execution involving lager number (thousands) of fine grained access control policies in Relational Database management systems. Current DBMSs cannot do this efficiently and Sieve comes up with an efficient query rewrite for doing policy evaluation. We need scalable data protection as organizations today capture and store large volumes of personal data that they use for a variety of purposes such as providing personalized services and advertisement. New data domains such as Internet of Things (IoT) capture data continously through sensors embedded in physical spaces to support location-based services. The data thus collected has several privacy implications. In recent years, we also have seen new privacy regulations such as the European General Data Protection Regulation(GDPR) and the California Online Privacy Protection Act(CalOPPA), and the Consumer Privacy Act (CCPA), that have made it necessary to empower user with data protection capabilities. A combination of new data domains and new regulations have resulted in a large number of fine grained access control policies. Our case study in the paper exemplifies this with a smart university classroom. In this example, we estimate that there will be upwards of 500 policies for the Professor who wants to query the data of his students for checking attendance.
Today, database management systems (DBMSs) implement Fine-Grained Access Control (FGAC) by one of the two mechanisms: 1) Policy as schema and 2) Policy as data. They are both based on query rewriting, by appending policies as predicates to the WHERE clause of the original query. However, these strategies introduce significant overhead to query execution. Sieve incorporates two distinct strategies to reduce overhead: reducing the number of tuples that have to be checked against complex policy expression and reducing the number of policies that need to be checked against each tuple. First, given a set of policies, it uses them to generate a set of guarded expressions that are chosen carefully to exploit the best existing database indexes, thus reducing the number of tuples against which the complete and complex policy expression must be checked. This strategy is inspired by the technique for predicate simplification to exploit indices. Second, Sieve reduces the overhead of dynamically checking policies during query processing by filtering policies that must be checked for a given tuple by exploiting the context present in the tuple (e.g., user/owner associated with the tuple) and the query metadata (e.g.,the person posing the query –i.e., querier– or their pur-pose). We define a policy evaluation operator ∆ for this taskand present an implementation as a User Defined Function(UDF). Sieve combines the above two strategies in a single framework to reduce the overhead of policy checking during query execution. Thus, Sieve adaptively chooses the best strategy possible given the specific query and policies defined for that querier based on a cost model estimation. We have evaluated the performance of Sieve using a real WiFi connectivity dataset captured in our building at UC Irvine and a synthetic dataset based on a shopping mall.